Propensity Score Matching In R
Https Rstudio Pubs Static S3 Amazonaws Com 179727 B3e8fc4eea3a4b6ea76c768dbad2df3a Html

Propensity Score Matching In R Youtube
Propensity Score Matching In R

Pdf Trimatch An R Package For Propensity Score Matching Of Non Binary Treatments Semantic Scholar

Plotting Density Function Of Propensity Score Before Matching Stack Overflow

Subgroup Analysis Propensity Score Matching Using R Studio In Download Table

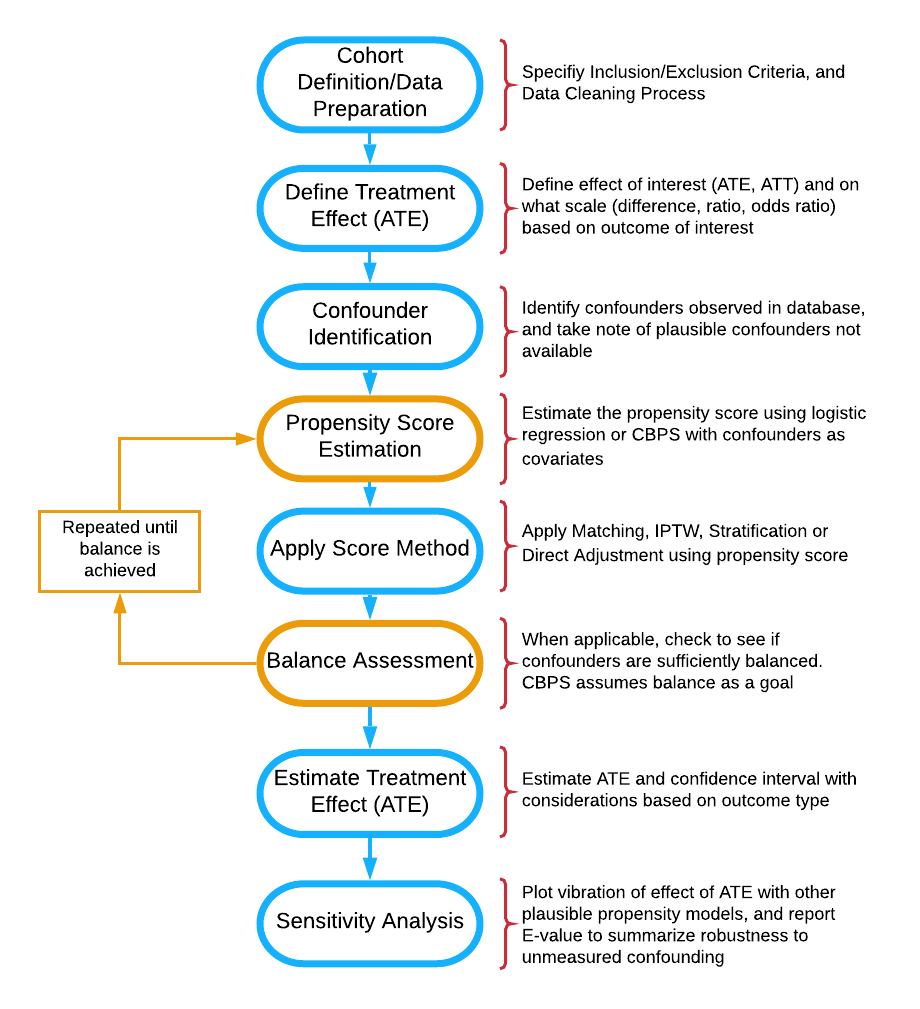
Propensity score matching psm paul r.
Propensity score matching in r.
Https Rpubs Com Cuborican Matching

How To Use R For Matching Samples Propensity Score R Bloggers
Https Support Sas Com Resources Papers Proceedings16 11420 2016 Pdf
Https Rpubs Com Kaz Yos Epi271 Lab3

The Problem With Propensity Scores I M Jacob
Veridical Causal Inference Propensity Score Tutorial With R Code

A Practical Guide To Propensity Score Analysis For Applied Clinical Research Sciencedirect

Propensity Score Analysis In Thoracic Surgery When Why And An Introduction To How Sciencedirect

Pdf A Step By Step Guide To Propensity Score Matching In R

Pdf A Practical Guide For Using Propensity Score Weighting In R Semantic Scholar

Summary Of Propensity Score Matching In Education Ppt Video Online Download

Getting Started With Matching Methods University Of Virginia Library Research Data Services Sciences
Http Jeb Sagepub Com Content Early 2016 03 11 1076998616631744 Full Pdf

Propensity Score Analysis

Propensity Score Matching In Stata Youtube
Something From Nothing Estimating Consumption Rates Using Propensity Scores With Application To Emissions Reduction Policies

Pdf A Tutorial On The Use Of Propensity Score Methods With Survival Or Time To Event Outcomes Reporting Measures Of Effect Similar To Those Used In Randomized Experiments

Exploring Propensity Score Matching Data Analyst Job Training Data Scientist
Https Encrypted Tbn0 Gstatic Com Images Q Tbn 3aand9gcq1nwmpchqodjjci861qinqcrjfvlsstf7foqujatnb6ao4yjrf Usqp Cau

Pdf Multivariate And Propensity Score Matching Software With Automated Balance Optimization The Matching Package For R
Propensity Score Matching Explanation Program Evaluation Scores Evaluation

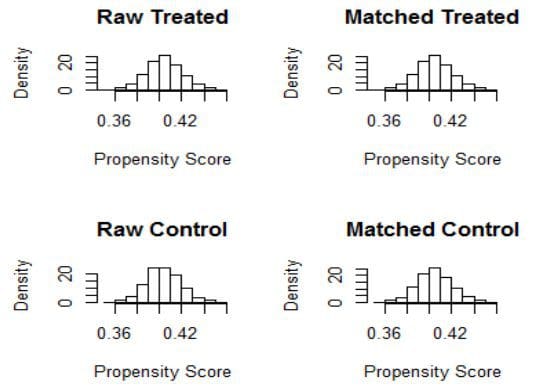
Pdf Balance Diagnostics After Propensity Score Matching

Propensity Score Matching A Quick Introduction Youtube
Http Www Math Umd Edu Slud S818m Missingdata Propensityscoreweightingr Pdf
Source : pinterest.com
